What if we would like to get data that we are not responsible for and analyze them ? How could we realize that ? How Python can help you making better life-travel decision in the future.
This is the purpose of this post and stay tune for a second part where I dig into the data.
Scraping Deutchbahn for Train ticket prices
First of all, I would like to say that I am not a hacker that would like to steal information from any website. It was just out of self interest that I came to think that I would like to know when should I buy my train tickets to come back to France.
I know for a fact that buying earlier is the less expensive option, we don’t need to run a deep analysis for that. What I wanted to know was when is the last moment before the price goes up. Is there any correlation between the the date of the request and the date of the travel.
How much an extra day of wait would cost me ?
This is with all of these questions that I started to create my code. I will show here some example of the issues that I encountered and how I bypass them. This will not be a guide to show you how to grab prices but it can give you tips on how to bypass some Web Scrapping issue.
1. Define what you really want to get
I know that this is a bit deceiving but the first step to realize this kind of task is actually not to code. Actually you should get a bit away from coding. You should first think of what you want to grab so you can analyze it later.
A good way to start here is too look at your target page(s), on mine you can identify :
- The destination
- The price
- 1st class
- 2nd class
- The duration
- The number of stops
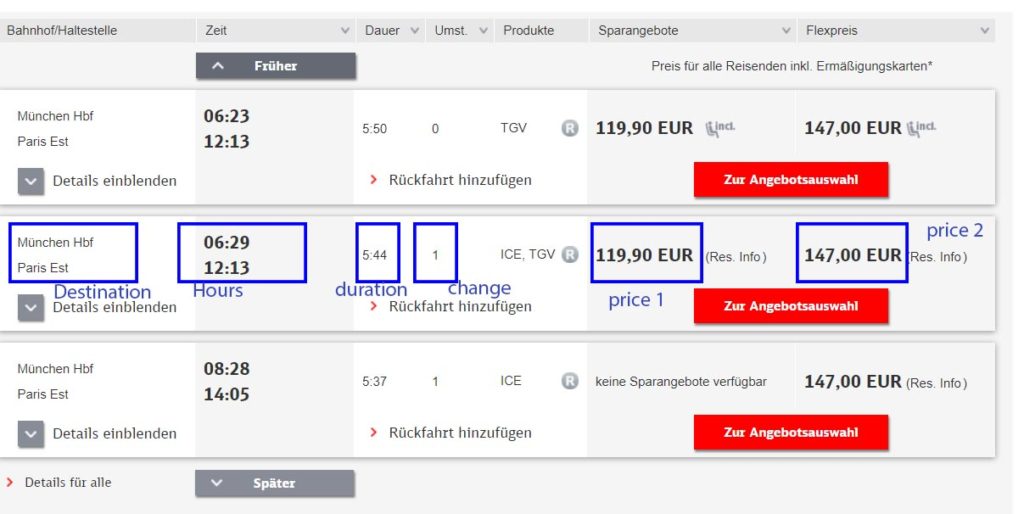
This is a good start to get your data in your system but then you need to consider when you are going to analyze those data. You will need to have context to know what exactly you are analyzing. So in addition to what you see on the page, I would always try to put more context information :
- Date of the departure
- Date of the request
- Delta between date of the request and the date of the departure
2. Find the parameters that will help you
When you are on your target page, you will need to find a way to get the parameter that you want to retrieve.
Basically, doing a bit of HTML research on the page.
There is nothing too hard to do here, so you can try to realize that.
3. Try to retrieve the page and the elements
Before you realize your first script with this request, you will need to first see if you are able to retrieve the elements that you have identified on the page.
So the first to do in Python will be to import some libraries, my recommendation to start would be :
- requests : library to request url (or other web resource)
- beautifulsoup : library to decode HTML elements.
- Normally you only import one part of this library, ie : from bs4 import BeautifulSoup as bs
- re : Regular Expression compiler, when you do a bit of scraping, you have to know a bit of Regular Expression.
The first challenge that we will encounter is that the page information are not so easy to read when you retrieve them with Python.
Basically, the information are hidden behind some JavaScript.
This is a good protection against basic scraping as the JavaScript need an environment to be processed, usually a browser. Therefore basic scripting are not good enough to retrieve the information you want.
We would need to have a way to bypass this protection if we really want to retrieve those data.
Fortunately Python comes with lots of solution and one of them is very well known from the tester that want to automate scraping: Selenium.
This tool is not designed to scrap the web but more likely to test specific functionalities on the websites. It can really automate some testing for you so it is really helpful and today it will definitely help us.
On the next section, we are going to start the most interesting part, which is the way that we are using Selenium.
4. Selenium (light) tutorial
So you will need to install selenium, the normal
pip install selenium
will do fine.
After that, the most important things to do is to download the 2 web driver for Chrome and Firefox, you can do it here :
- Chrome : http://chromedriver.chromium.org/downloads
- Firefox : https://github.com/mozilla/geckodriver/releases
Once you have downloaded them, you can extract the EXE files and place them where Python can access them. Personally I set the folder python3.X/scripts in the window environment path and therefore I placed the EXE files there.
when you call selenium in your script, you can only select the webdriver, because this is the only thing that we want.
from selenium import webdriver
I would also recommend to configure some option to your webdriver before you use it :
options = webdriver.ChromeOptions()
options.add_argument('--ignore-certificate-errors')
options.add_argument('--ignore-ssl-errors')
driver = webdriver.Chrome(chrome_options=options)
driver.implicitly_wait(6)
The last one is quite important because you will have to let the driver stand a bit before requesting the next page.
If you just asked all of your pages one after another, the page doesn’t have the time to render that the next request is sent.
In addition to that, I used a time.sleep(3) for making sure that my code pause a moment.
The function to request an URL with Selenium is quite pythonic :
driver.get(url)
What you need to do, once you get the URL is to make sure that you have the HTML that is render by the JavaScript.
If you are not careful, you can end up by doing a simple HMTL scrap and you are back to square one : HTML element that need to be render by JS.
In order to do that, you will execute a script and keep that HTML in an object. After that, it is just a matter of storing that object, a list seems pretty good if you request multiple pages.
html = driver.execute_script("return document.body.innerHTML")
At the end, as for a file, you need to think of closing your driver / browser.
driver.close()
When you know all of this, this is just a matter of Python script.
5. Logic for your Python script
As I explained a bit at the beginning of that article, I cannot give you directly the script for scraping the Deutschbahn.
First – not fair to the Deutschbahn
Second – you would learn much more by trying to do the script by yourself
What I can give you is some logic thinking of your script :
- try to figure out which element to retrieve and store it in a single dictionnary.
This way, you have only one place to update when the template change.
example :
dict_db = {##Element to retrieve from DB
“box” : {
“element” : “tbody”,
“class” : “boxShadow scheduledCon”
},… - prepare your calendar of request in advance :
today = datetime.date.today()
day_1 = today + datetime.timedelta(days=1)
day_2 = today + datetime.timedelta(days=2)
day_3 = today + datetime.timedelta(days=3)
and store it in one place :
list_days = [day_1,day_2,day_3] - if you already know what to retrieve, and you should if you prepare your project, you can start building your dataframe.
Ex :
columns = [‘request_date’,’travel_date’,’time_delta’,’start_time’,’end_time’,’duration’,’change’,’price_2′,’price_1′,’transportation’]
df_all = pd.DataFrame(columns=columns) - I would always recommend to use to not having index when you save your file AND using tabulation for separating the columns.
You can never know if they are going to use “.” or “,” on the website you scrap.
Tab is a good choice :
df.to_csv(‘data_train.csv’,sep=’\t’,index=False)
next steps :
After realizing this script and making it run for some time, I will come back with an article on some analysis I can do with these data.
It will be the part 2 of this post, stay tuned for this post.