
In this article, I would like to introduce a revolution that I started months a year ago (yeah, I have no time to update you anymore – sorry – watch my githubs 😉 ). And trust me, revolution is the right word.
As I am using my aepp library (a lot) to manage the AEP implementation of my clients, I always felt that I was missing a capability to handle schemas in a more productive way.
The UI is doing a good job at simplifying the creation of the schema, and field groups, it may be too good actually as most people do not realize when they are editing schema or field groups anymore.
The aepp library is providing an easy access to the Schema Registry API but except for some nice wrapping method (createExperienceEventSchema, createProfileSchema, etc…) I was not feeling content with the capabilities I was offering.
In comparison, I could use the Catalog or Ingestion submodules much more frequently and with a higher efficiency multiplier.
The challenge came from the complexity of a Schema and how difficult it is to handle the schema definition. Only using the Schema Registry API would not give you much more than an easy way to download Schema, Class and Field Groups.
However, what you see from the UI is a very simplify version of what the API get (actually what multiple API requests get).
For understanding the complexity of the XDM setup, I would encourage you to read my article about it: The Ultimate Guide on XDM Schemas.
With that knowledge on how the behavior of Schemas and Field Groups work, I could leverage the API to better handle them.
This is where I introduce to you the Schema Manager and Field Group Manager. (tada!)
These are 2 (incredible) classes of the schema module, that let you handle these artefacts in a very easy way via a command line interface, either via python environment or, as I am always using, via Jupyter Notebook or Lab.
Field Group Manager
As explained in my long article on the XDM schemas, the Field Groups are the basis of your schemas. Therefore, we will explain that class and the management of that artifact first. The SchemaManager will basically inherit all getters of the field groups it has. Also, every modification of your schema needs to be done on Field Group level anyway, so make sense to explain what possibility is there first.
You have a complete documentation of that class and its method here: https://github.com/adobe/aepp/blob/main/docs/fieldGroupManager.md
Once you have this class instantiated, you can start to realize some pretty cool stuffs regarding field group analysis, modification and export without the use of the UI.
Attributes
The first thing I want to provide is the available attributes for that instance:
- id : The $id of the fieldgroup
- altId : the meta:altId of the fieldgroup
- fieldgroup : the fieldgroup dictionary
- STATE : the different states are “NEW” or “EXISTING” (we’ll come back to that)
- EDITABLE : an attribute that define if you can actually modify this field group (out-of-the-box field groups are not editable or field groups that contain complex Data Type)
- title : The title of the field group
- tenantId : The tenant ID of your organization
For the methods, I will not review all the methods that are described in the Github but I will highlight 5 of them, and you better read them, even if you are only interested with the Schema Manager, because most of them are also available on Schema Manager.
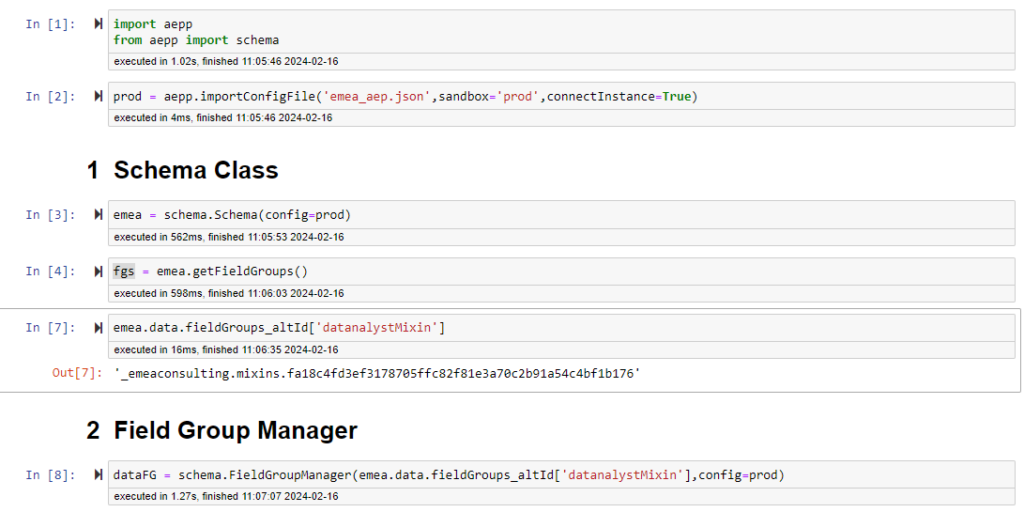
searchField
The searchField method provides a way to search for a specific field name. You can pass 3 arguments to it:
- The string you are looking for
- If you want to use partial match (default True)
- If you want to remove the case sensitivity for your search (default False)
This will return a list of the element definition that match your search.
In the result, you also have 3 additional attribute return for each search result.
- The complete path (usually contains “properties” for object)
- The simplified path (dot notation that you see in the UI with annotation for object and list)
- The query Path (the dot notation for query service)
This can be really helpful in order to build information on what path is possible to query.
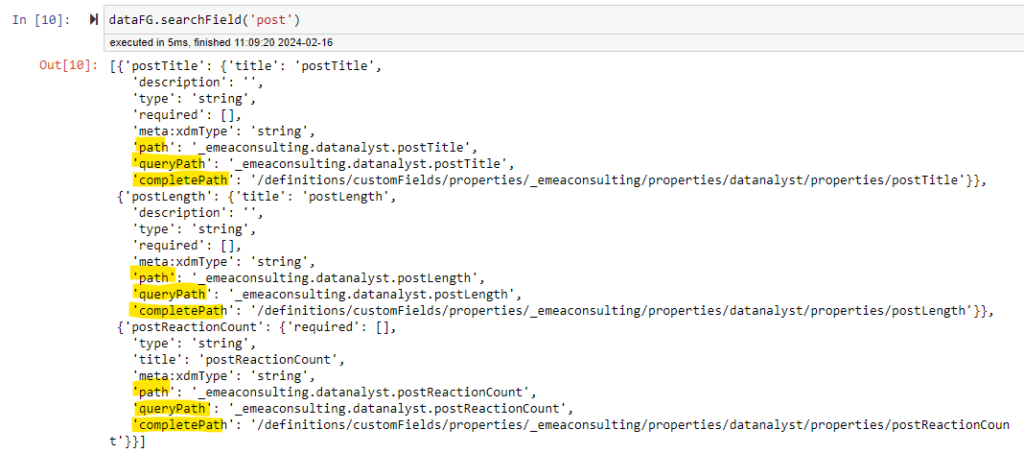
Search Attribute
This method helps finding fields that have specific attribute.
The common use-case is to try to find the fields that are double, or array.
Because you do not always remember the name of your field or if you do not want to search by name (title in schema reference) but by another attribute.
It accepts 4 parameters:
- attr : REQUIRED : a dictionary of key value pair(s). Example : {“type” : “string”}
NOTE : If you wish to have the array type on top of the array results, use the key “arrayType”. Example : {“type” : “array”,”arrayType”:”string”}
This will automatically set the joinType to “inner”. Use type for normal search. - regex : OPTIONAL : if you want your value of your key to be matched via regex.
Note that regex will turn every comparison value to string for a “match” comparison. - extendedResults : OPTIONAL : If you want to have the result to contain all details of these fields. (default False)
- joinType : OPTIONAL : If you pass multiple key value pairs, how do you want to get the match.
- outer : provide the fields if any of the key value pair is matched.
- inner : provide the fields if all the key value pair matched.

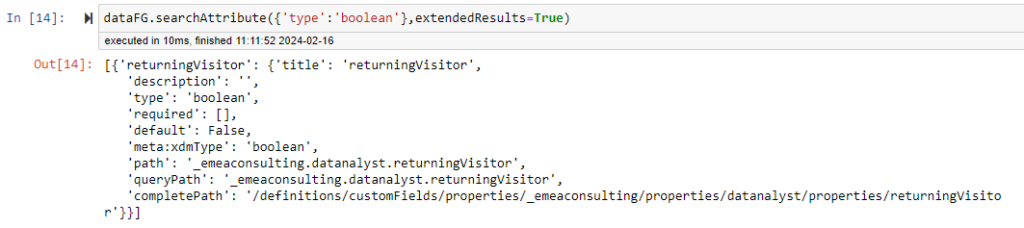
addField
This is where it gets really interesting, for any Field Group that are EDITABLE, you can add field by passing some parameters. The field will be added in your local copy but once you use the updateFieldGroup method, you will send this update to Adobe Experience Platform.
This method can take 9 parameters, so you can imagine it was quite complex to code:
- path : REQUIRED : path with dot notation where you want to create that new field. New field name should be included.
- dataType : REQUIRED : the field type you want to create A type can be any of the following: “string”,”boolean”,”double”,”long”,”integer”,”number”,”short”,”byte”,”date”,”dateTime”,”boolean”,”object”,”array” NOTE : “array” type is to be used for array of objects. If the type is string array, use the boolean “array” parameter.
- title : OPTIONAL : if you want to have a custom title.
- objectComponents: OPTIONAL : A dictionary with the name of the fields contain in the “object” or “array of objects” specify, with their typed. Example : {‘field1:’string’,’field2′:’double’}
- array : OPTIONAL : Boolean. If the element to create is an array. False by default.
- enumValues : OPTIONAL : If your field is an enum, provid a dictionary of value and display name, such as : {‘value’:’display’}
- enumType: OPTIONAL: If your field is an enum, indicates whether it is an enum (True) or suggested values (False)
possible kwargs: - defaultPath : Define which path to take by default for adding new field on tenant. Default “property”, possible alternative : “customFields”
- description : if you want to add a description on your field
Let’s see 3 specific parameters.
defaultPath: by default the operation will try to use the property path on your Field group definition, however, if most of your Field Group has been created by the UI, it is most likely that the path is contained in the customFields path.
objectComponents : When creating a new field that is of type object, you cannot create an empty object, so you would need to pass one element by default. So at least pass one {key:value} pair.
array : Sometimes, you want to have a field that can contain array of string. In that case, you need to define the field type as string and set the array parameter to True.
If you have read and understood the blog post I did on the XDM explanation, this method does not exist for the Schema Manager.
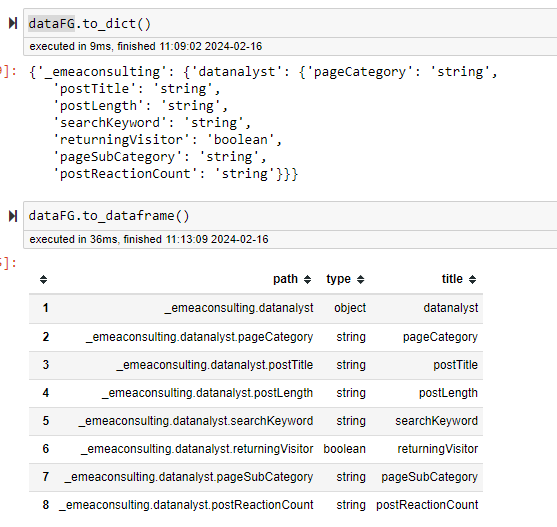
to_dataframe and to_dict
These methods are ultra powerful in order for you to create your documentation in an easy, fast and reliable way.
They basically output the Field Group as dictionary, so compatible to create JSON payload template and DataFrame (famous from the pandas library that handle numpy array).
The dataframe capability offers more options as I can extend the dataframe with more columns depending on the parameter passed.
To deep dive on the to_dataframe methods, here are the parameters:
- save : OPTIONAL : If you wish to save it with the title used by the field group. save as csv with the title used. Not title, used “unknown_fieldGroup_” + timestamp.
- queryPath : OPTIONAL : If you want to have the query path to be used.
- description : OPTIONAL : If you want to have the description used (default False)
- xdmType : OPTIONAL : If you want to have the xdmType also returned (default False)
- editable : OPTIONAL : If you can manipulate the structure of the field groups (default False)
Both methods are available in the Schema Manager as well. So you can document and generate payload directly at Schema Level.
Note: The Schema Level will not return the class specific fields (_id, timestamp, etc…).
importFieldGroupDefinition
Finally, if you have reached this far, you won’t be disappointed as I will present you one of the key feature of this FieldGroup Manager.
The importFieldGroupDefinition allows you, for any field group to edit description and title of any fields… directly via an Excel, a CSV file or via a pandas dataframe.
There are 3 prerequisite for the data you want to use:
- Having a path column
- Having a type column
- Having a fieldGroup column
The other possibilities are optional:
- title
- descriptions
Wait a minute… if title and descriptions are optional, why would you need the 3 columns in your CSV/Excel file ?
I was saying that all field groups field title and descriptons can be edited but for field groups with EDITABLE attribute returning True, you can also simply add any field or path to these field groups directly via a modification in your file.
Yes, you read it correctly. You can use Excel or CSV to edit field groups!
You obviously need to upload the files via this method and do some checks (you’ll see lated) but that makes modification, documentation and managing field groups a lot easier.
And one last words, you can also use a CSV or Excel file (or pandas dataframe) to actually create Field Group from scratch (!!).
You can create Field Group Manager instance without any defintion specified, just passing the config that you have loaded and create a Field Group by importing the file. You can use that file as reference and edit and upload it anytime you need to.
I think that should be a start of a revolution.
After the importFieldGroupDefinition method has been ran, you can actually check if the definition is imported correctly by running the searchField or getField. Once you have been doing that verification, you can use updateFieldGroup or createFieldGroup to actually upload the (new) definition to AEP.
Schema Manager
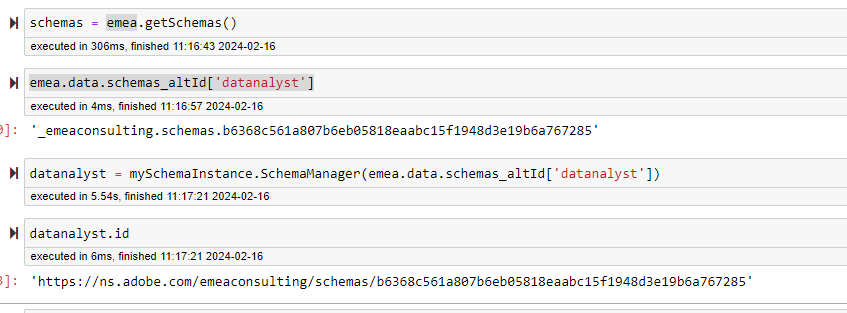
You can instantiate the Schema Manager directly from the Class defined in the schema module, or via your instance of Schema class. Everything is described directly in the github.
We will describe the methods specifically available for Schema Manager below but first the attributes available for a Schema Manager instance are:
- id : The $id of the schema
- altId : the meta:altId of the schema
- title : the title of the Schema
- fieldGroups : A dictionary of the Field Group Name and ID.
- fieldGroupIds : the list of field group IDs
- fieldGroupTitles : the list of the field group titles
- STATE : If the schema is a new one or an existing one
- tenantId : The tenant ID of your organization
Main Schema Manager methods
Almost all of the methods described above are also available in the Schema Manager, because schema manager actually delegates most of the searches to each of the Field Groups that are composing the schema.
Nevertheless, there are some specifics important information about some methods.
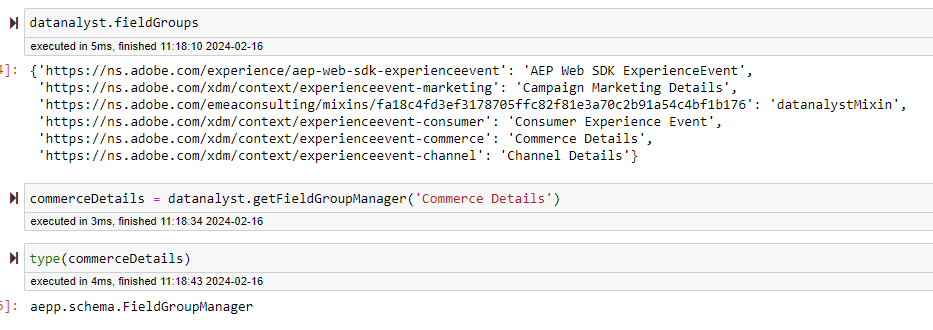
getFieldGroupManager
This method allows you to get any Field Group via the Field Group Manager instantiated behind the Schema Class. Accessing the Field Group Manager will permit you to edit the Field Group and, per example, add a field if you want. Any change made to the Field Group will be replicated to the schema.
You can retrieve a field group manager instance by passing the id of the field group or its name.
addFieldGroup
In case you want to add a new field group to your schema, you can use this method and it will automatically add the Field Group in the schema definition.
First locally, then you can use the updateSchema method to push that change to Adobe Experience Platform.
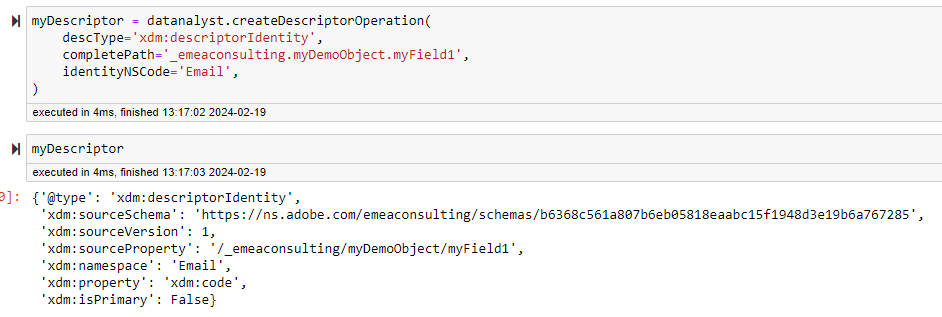
createDescriptorOperation
This method will help you prepare a descriptor for a schema.
A descriptor is a tag that you associate with one field of your schema, the main examle would be when you set an identity on your schema.
When setting an identity on your schema, you basically place a tag on one of your field, and define the type of tag is being applied here, in this example, it would be a “xdm:descriptorIdentity“
Because creating descriptor can be quite complicated, the schema manager will try to simplify your work (again). Using this method will guide you and return the JSON to be used in the createDescriptor method.
importSchemaDefinition
By now, if you did not jump over the Field Group methods description, you will now realize that the method available for Field Group, knowingly, creating Field Group by using a CSV or Excel file for the definition, can be now used for Schema.
What is the difference you may ask ?
The thing is that now you can directly define all of the fields of that Schema and their Field Groups, even if they do not exist already. The Schema Manager will take care of creating the field group for you.
Obviously working with CSV or Excel works mostly for non OOTB field groups.
I would be recommended to pass the OOTB field groups to your schema by adding them directly via the addFieldGroup method and not trying to define them in the Excel or CSV.
Once you have run this method, it will return a dictionary with the keys being all of the Field groups you have defined in your CSV or Excel, and then you can check each one of them, because the Field Group Manager of these field groups will be returned.
Once you are happy with these changes, you can run the applyFieldChanges method to create or update all of your field groups.
In case, your schema do not exist yet, you will need to run the createSchema method afterward.
I hope this long article was clear for you to see what type of revolution I am bringing into the AEP experience. I hope you will like these features and bring some feedbacks.
Have fun
Note: You can also change the custom Data Type via the DataTypeManager.